Build an RL (Reinfrocement Learning) agent that learns to play Numerical Tic-Tac-Toe
One of the most popular and enduring games of all time is Tic-Tac-Toe. Because of its familiarity, this game is often used as a starting example to mathematically analyze a decision-making process. Its brevity makes it a perfect game to illustrate the rewards of thinking ahead and learning the consequence of each decision.
There are many variants of Tic-Tac-Toe. The most classic one is of X’s and O’s, where each player aims to place three of their marks in a horizontal, vertical, or diagonal row in a 3x3 grid.
The other popular variant of this game is Numerical Tic-Tac-Toe. Instead of X’s and O’s, the numbers 1 to 9 are used. In the 3x3 grid, numbers 1 to 9 are filled, with one number in each cell. The first player plays with the odd numbers, the second player plays with the even numbers, i.e. player 1 can enter only an odd number in the cell while player 2 can enter an even number in one of the remaining cells. Each number can be used exactly once in the entire grid. The player who puts down 15 points in a line - (column, row or a diagonal) wins the game.
Rules of the Game:
-
The game will be played on a 3x3 grid (9 cells) using numbers from 1 to 9. Each number can be used exactly once in the entire grid.
-
There are two players: one is the Reinforcement Learning (RL) agent and other is the environment.
-
The RL agent is given odd numbers {1, 3, 5, 7, 9} and the environment is given the even numbers {2, 4, 6, 8}
-
Each of them takes a turn. The player with odd numbers always goes first.
-
At each round, a player puts one unused number on a blank spot.
-
The objective is to make 15 points in a row, column or a diagonal. The player can use others numbers in the grid to make 15.
-
The game terminates when any one of the players makes 15.
In this project, we will build an RL agent that learns to play Numerical Tic-Tac-Toe with odd numbers (the agent will always make the first move). You need to train your agent using Q-Learning. The environment is playing randomly (no strategy) with the agent. If your agent wins the game, it gets 10 points, if the environment wins, the agent loses 10 points. And if the game ends in a draw, it gets 0. Also, you want the agent to win in lesser number of moves, so for each move, it gets a -1 point.
Following is a sample episode for your reference:
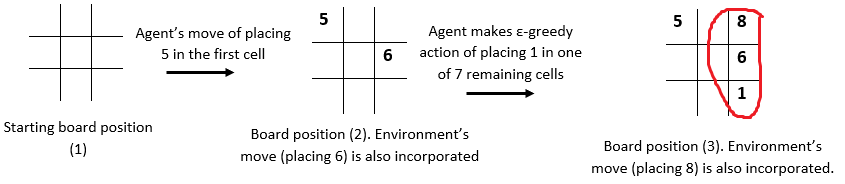
In this episode, the environment wins as it is able to make 15 first (8+6+1). After the agent places 1 in one of the grids, the environment rewards it (with a negative reward of -1) and makes a next move of placing 8 in one of the remaining cells.
Steps:

